
Using Elastic Search highlighting is normally straightforward. But sometimes we have a piece of text that contains other information. For example we may have a text the contains html tag or other information that we want to ignore. In these cases using the normal highlighting does not give us the result we’re seeking. For example suppose a text contains html tags and we want to search for the keyword “section”. The problem is our highlighter is also going to highlight a HTML tag. There’s way to fix this issue. We can do this by instructing elastic search highlighting to ignore html tags.
So in this post first I’m going give some introductory info about elastic search highlighting. After that we’re going to see how we can ignore html tags in our highlighting request.
Elastic Search Highlighter Basic Usage
Let’s first create some sample data and then examine how the highlighter works.
Now lets assume that we want to search for “organized” in Description and DescriptionHtml.
Here’s what we get as a result.
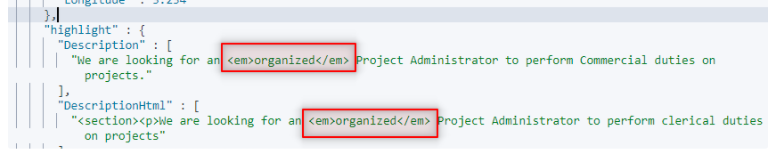
As you can see we received another field along what we have in source called highlight. Also the search keyword is wrapped inside em html element. It is not important whether the test we want to use highlighter for already have html tags or not, in both cases the keyword we’re looking for is going to be wrapped.
Currently we can’t use the DescriptionHtml because if we search for a text which have the same name as a HTML tag, it is going to break the HTML.

We’ll see how to fix this issue in subsequent section.
Elastic Search Highlighter Settings
The Highlighter can be tweaked in many different way as described in this document. Here I try to show some relevant settings that we might want to use.
Elastic Search supports three types of highlighter, unified (the default), plain, and fvh (fast vector highlighter). If you want to highlight a lot of fields in a lot of documents with complex queries, it is recommended to use the unified highlighter.
We can specify the type of highlighter that we need to use like so, keep in mind some type of highlighters like fvh also need mapping changes.
Controlling the HTML Element that Wraps the searched keyword
It is possible to change the html element used to wrap the keyword.
If you run this query you’ll see that for Descriptionfield, the keyword “organized“ is wrapped with <b> element instead of <em>. Here I quote from the elastic reference document.
pre_tags
Use in conjunction with post_tags to define the HTML tags to use for the highlighted text. By default, highlighted text is wrapped in <em> and </em> tags. Specify as an array of strings.
post_tags
Use in conjunction with pre_tags to define the HTML tags to use for the highlighted text. By default, highlighted text is wrapped in <em> and </em> tags. Specify as an array of strings.
tags_schema
Set to styled to use the built-in tag schema. The styled schema defines the following pre_tags and defines post_tags as </em>.
Overhead in non-empty arrays
There is a small amount of overhead involved with setting matched_fields to a non-empty array so always prefer
Specifying the size of Highlighted Fragment
Each field highlighted can control the size of the highlighted fragment in characters (defaults to 100), and the maximum number of fragments to return (defaults to 5). For example:
Here we specified for Description field we only want 5 fragments as opposed to DescriptionHtmlwhich specified as zero (which means we receive everything). If the number_of_fragmentsvalue is set to 0 then no fragments are produced, instead the whole content of the field is returned, and of course it is highlighted. This can be very handy if short texts (like document title or address) need to be highlighted but no fragmentation is required. Here’s how the query result will look like.
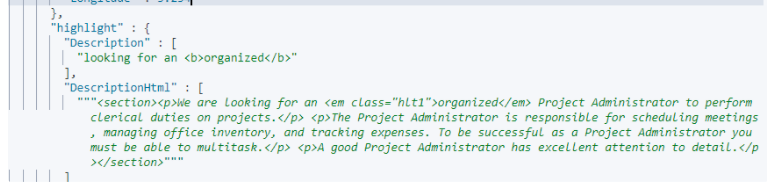
As can be seen we returned smaller portion of the text for Description field. Here I quote some part of elastic reference that explains the two settings that used here.
number_of_fragments
The maximum number of fragments to return. If the number of fragments is set to 0, no fragments are returned. Instead, the entire field contents are highlighted and returned. This can be handy when you need to highlight short texts such as a title or address, but fragmentation is not required. If number_of_fragments is 0, fragment_size is ignored. Defaults to 5.
fragment_size
The size of the highlighted fragment in characters. Defaults to 100.
For more info here is the section from the reference document.
Highlighting a Text That Contains HTML
As discussed in previous section, when we try to highlight a word that is also an HTML tag, we might encounter a problem. To solve this problem we can use a custom analyzer that ignores HTML tags in our search. Here’s an example of how we can use it.
Creating an Analyzer that ignores html tags
Here we are creating a custom analyzer. We call it ignore_html_tags in this case. Then we’re going to apply it to the field that we want to use the elastic search highlighting on.
As you can see in the code excerpt above on line 25, we applied the analyzer to DescriptionHtml field. Also this alanyzer internally uses a HTML strip character filter to filter out the HTML. Now if we execute the above query this query.
It produces the following result.

As we can see here even though we had a HTML tag called section which had the same name as the the word we were looking for in the query, the HTML tag get ignored and only we see the word section highlighted.
Summary
In this post I described how we can use elastic search highlighting and its basic settings. We also saw how we can ignore html tags inside the text that we’re highlighting.
“html_strip” doesn’t work when you use adjacent tags like:
Section, when you search “Section” it will highlight:
Section
Because the tokenizer generates offset including the tag. Which is very annoying. We do a postprocessing step to avoid this inner tags.